
Reflections on the tune split
It is standard practice in natural language processing to split our datasets into three parts: train, dev, and test. The train split can be used to train the model, and the development set is used to evaluate the model during the development phase. Finally, our most promising/interesting models can be evaluated against each other on the test set. In practice, for a new addition/improvement to a model, this would mean that one would train multiple versions of this model (for example for hyperparameter tuning), and evaluate these on the dev data, and the best (or most interesting) model is then compared to the baseline and previous work (i.e. state-of-the-art).
Since the introduction of neural networks, the usage of these standard splits has shifted a bit. Since most approaches make use of model selection and early stopping, the dev set is already used in the training procedure. People have noticed that the internal models can now not fairly be compared on the dev split anymore, and have started to use the test data for this. To quantify this issue, I have counted for 100 random papers from ACL 2010 and 2020 how many runs on each test set where made in each paper. The results confirm a clear trend; in 2020, many more test-runs were made per paper.
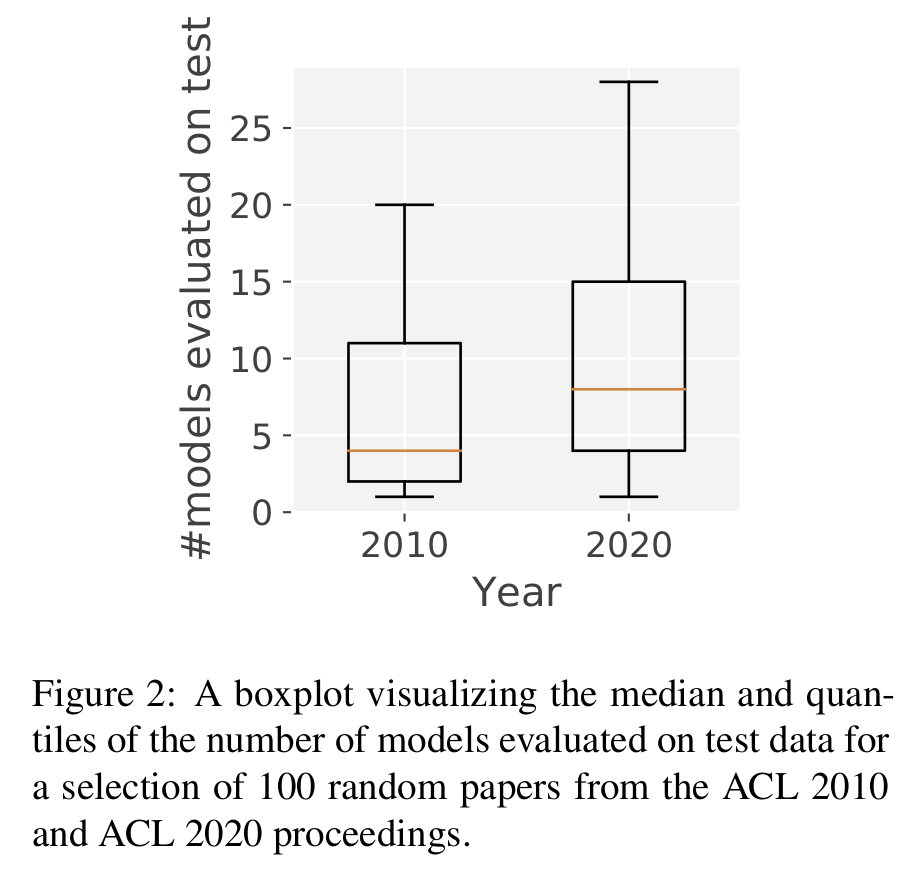
The solution I proposed in my 2021 EMNLP paper (van der Goot, 2021), was to use a tune split, which we can use to tune the model (i.e. early stopping and/or model selection). However, after having used the tune set for multiple experiments, I became frustrated by the additional complications in the setup that were caused by needing an additional split. First, one needs to have plenty of data, otherwise extracting one other split can have a substantial effect on performance. Second, now we can not directly use the models we used during experimentation, but have to train yet another model on train+tune for our final runs. Third, whenever using existing datasets, I had to come up with a new splitting strategy. For example, in the original tune split paper, I proposed to concatenate all sentences in a UD treebank, and use the last 3,000 sentences for dev- tune- and test-splits. However, later I realized that the test data is more important, and the size of dev and tune can/should be a function of the total size. Hence, in a TLT 2021 paper, we split by the following strategy: ``for datasets with less then 3,000 sentences, we use 50% for training, 25% for tune, and 25% for dev, for larger datasets we use 750 sentences for dev and tune, and the rest for train.’’ (we kept the test data untouched here).
Perhaps it is time to take another look at the source of the problem. I argued that because we used the dev set for model selection people tend to stop using it for model comparison. The solution is to not use the dev split for model selection, this is where the tune split came in. But there is another way to avoid model selection on the dev set; namely consider the amount of epochs to train for a normal hyperparameter, which we tune once and then set to a certain number for the rest of the experiments. Note that model selection is indeed just a hyperparameter, however it can be considered special because it is often tuned for every single instance of the model, whereas other hyperparameters (e.g. dropout, learning rate, etc.) are tuned once and then kept frozen. Here, I propose to drop this special status.
In practice, I usually use the default hyperparameters of MaChAmp, which uses a slanted triangular learning rate scheduler. I already always disabled early stopping, as the learning rate is dynamic (see the image below), it is never safe to assume that performance has converged. Besides, the decreasing trend of the learning rate lowers the chance of overfitting, so actually just taking the model of the last epoch is an easy and relatively safe option here. Note though, that the number of epochs should now probably be tuned. We inspected the effect of the learning rate and the numbers of epochs a while back (see also this blog), and found that 20 epochs and a learning rate of 1e-04 result in a good balance between efficiency and performance.
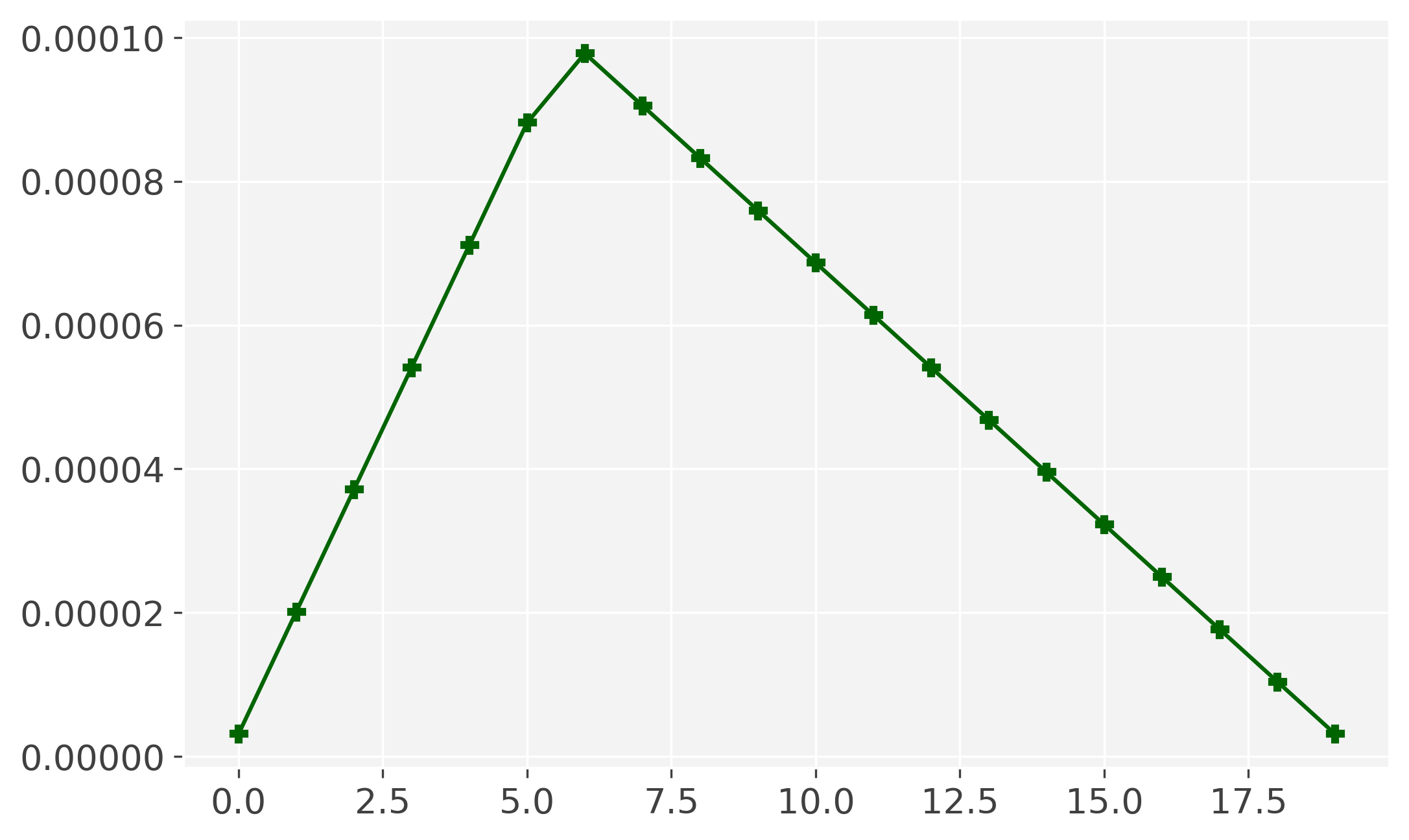
Learning rate values with slanted triangular scheduler and a cut_frac of 0.3 and a decay factor of 0.38 (default in MaChAmp).
Comments