
An empirical comparison of multi-lingual language models
There is a larger and larger variety of language models available, making it harder to pick the right one. The most widely useful language models are the massive multi-lingual ones, as they enable easy multi-lingual model, and even cross-lingual they have shown to perform well. I have evaluated all the multi-lingual (> 20 languages) pre-trained language models I could find on two popular NLP benchmarks; GLUE and UD. I have used MaChAmp v0.4 beta for these experiments, with default settings (tuned on mBERT and XLM-r large).
I selected subsets from both datasets to make running these experiments feasable. For UD I used the subset from Smith et al. (2018). For GLUE the main constraint was training time, I used: CoLA, QNLI, RTE, SST-2 STS-B. Note that this is not an extensive study, but just a quick try-out; the LM is tuned on two of the language models and the selection of task might not representative, reported scores are over a single run.
The language models I found were:
multiRegressive = \['Helsinki-NLP/opus-mt-mul-en', 'bigscience/bloom-560m', 'facebook/mbart-large-50', 'facebook/mbart-large-50-many-to-many-mmt', 'facebook/mbart-large-50-many-to-one-mmt', 'facebook/mbart-large-50-one-to-many-mmt', 'facebook/mbart-large-cc25', 'facebook/mgenre-wiki', 'facebook/nllb-200-distilled-600M', 'facebook/xglm-564M', 'facebook/xglm-564M', 'google/byt5-base', 'google/byt5-small', 'google/canine-c', 'google/canine-s', 'google/mt5-base', 'google/mt5-small', 'sberbank-ai/mGPT'\]
multiAutoencoder = \['Peltarion/xlm-roberta-longformer-base-4096', 'bert-base-multilingual-cased', 'bert-base-multilingual-uncased', 'cardiffnlp/twitter-xlm-roberta-base', 'distilbert-base-multilingual-cased', 'google/rembert', 'microsoft/infoxlm-base', 'microsoft/infoxlm-large', 'microsoft/mdeberta-v3-base', 'setu4993/LaBSE', 'studio-ousia/mluke-base', 'studio-ousia/mluke-base-lite', 'studio-ousia/mluke-large', 'studio-ousia/mluke-large-lite', 'xlm-mlm-100-1280', 'xlm-roberta-base', 'xlm-roberta-large'\]
too_large = \['facebook/xlm-roberta-xxl', 'facebook/xlm-roberta-xl', 'google/byt5-xxl', 'google/mt5-xxl', 'google/mt5-xl', 'google/byt5-xl', 'google/byt5-large', 'google/mt5-large', 'facebook/nllb-200-1.3B', 'facebook/nllb-200-3.3B', 'facebook/nllb-200-distilled-1.3B'\]
Experiments are run on 32gb v100 GPU’s. We excluded language models with an average score lower than .7 for UD and .8 for GLUE in the graphs for reability. We sorted the language models first by type (regressive/autoencoder), and then alphabetically, so that the language models with multiple versions appear next to each other.
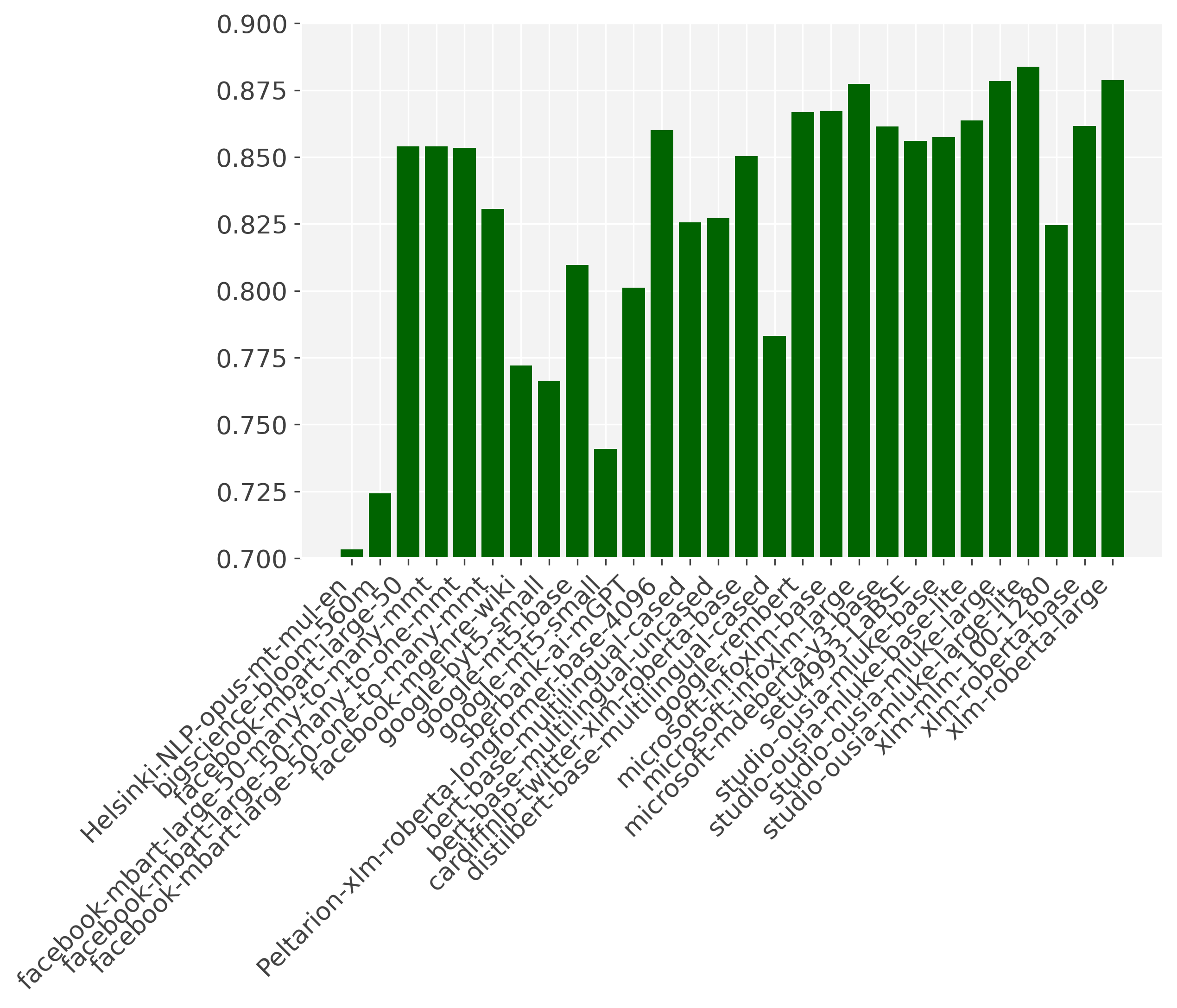
The mLUKE (Yamada et al. 2020) embeddings do very well in this experiment. They are pretrained on both word and entities. In the lite versions of LUKE, the entity embeddings are removed to save memory, performance should be highly similar if the entity embeddings are not used (altough in our case mLUKE lite does slightly better). Besides the difference in training objective, performance could also be higher due to smaller amount of languages used (25, whereas most others have around 100), this has shown to have an effect on performance (Conneau et al. 2020). We can also see that the commonly used XLM-r large still performs well (on par with mLUKE large and infoXLM). Altough the original authors discourage the use of uncased mBERT, it outperforms mBERT in this setup (as previously shown in van der Goot et al, 2022).
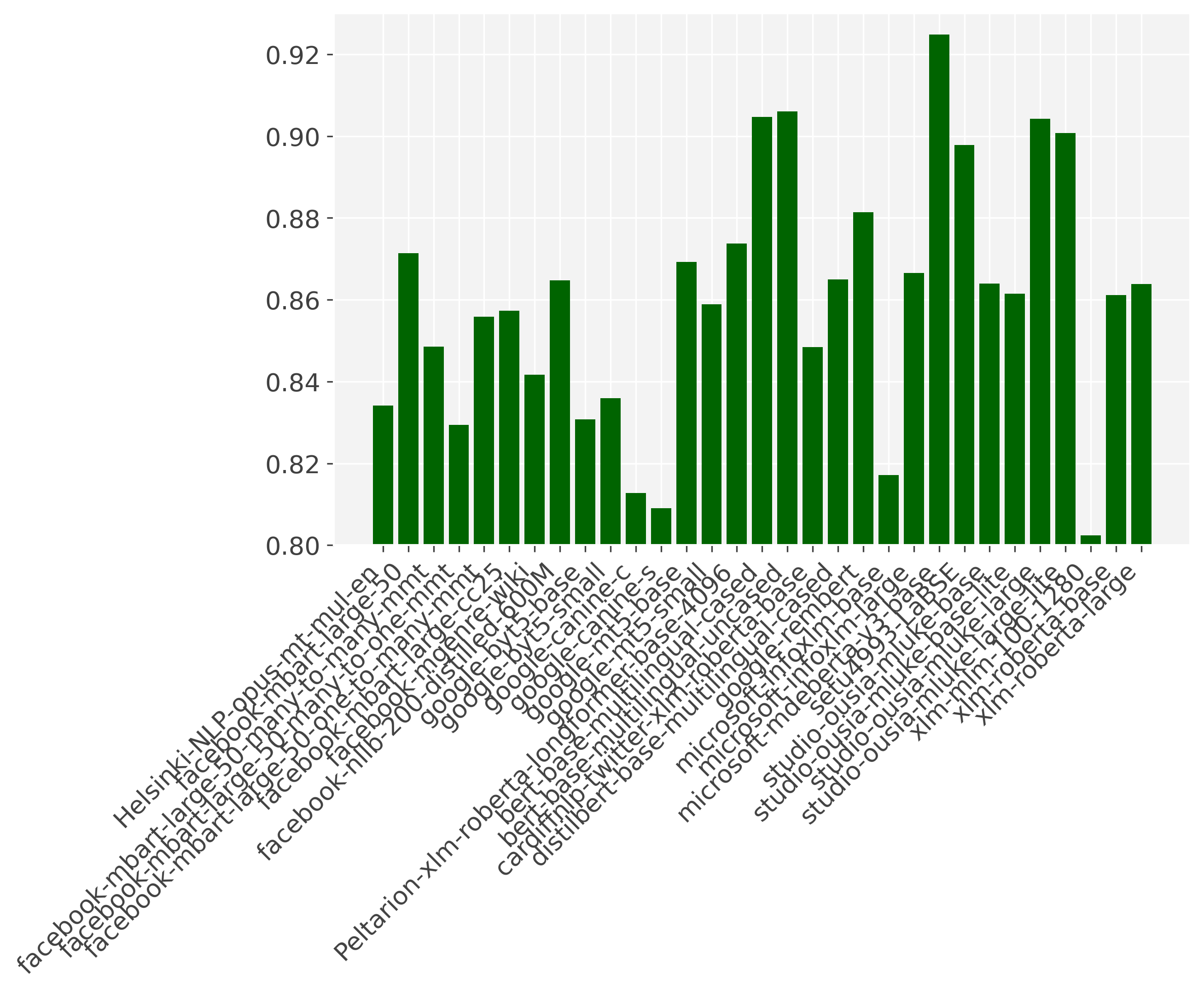
For the GLUE tasks, mDeBERTa outperforms the others by a large margin. Also here the uncased version of mBERT outperform the cased version. The differences are larger on these datasets, as it is a smaller sample, and we only included the smaller sets of this benchmark. The original multi-lingual BERT models do remarkably well on GLUE, ranking 2nd and third. Unsurprisingly, the autoregressive models underperform on both of these benchmarks (as they are trained with a sequence to sequence objective), altough mBART still performed somewhat competitive on UD.
Code for these experiments is available on https://bitbucket.org/robvanderg/tune-lms/
Comments